The technique of integration that is generally taught in a second semester calculus course is called Riemann integration. This is given by taking a closed, bounded interval ![\left[a, b\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5Ba%2C+b%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) and partitioning it into a set of points
and partitioning it into a set of points  where
where  . Given a function
. Given a function ![f : [a, b] \to \mathbb{R}](https://s0.wp.com/latex.php?latex=f+%3A+%5Ba%2C+b%5D+%5Cto+%5Cmathbb%7BR%7D&bg=ffffff&fg=000000&s=0&c=20201002) we then consider sums of the form
we then consider sums of the form
![\displaystyle \sum_{k=1}^n f(y_k) [x_k - x_{k-1}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bk%3D1%7D%5En+f%28y_k%29+%5Bx_k+-+x_%7Bk-1%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
where ![y_k \in [x_{k-1}, x_k]](https://s0.wp.com/latex.php?latex=y_k+%5Cin+%5Bx_%7Bk-1%7D%2C+x_k%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Sums such as this are called Riemann sums. In particular, we’d like to consider Riemann sums where the
. Sums such as this are called Riemann sums. In particular, we’d like to consider Riemann sums where the 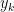 we choose in each sub-interval of the partition is the one that gives us the largest value of
we choose in each sub-interval of the partition is the one that gives us the largest value of  over that subinterval. Defining
over that subinterval. Defining 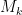 and
and  as follows, we can then do this easily.
as follows, we can then do this easily.
![\displaystyle M_k = \sup_{x \in [x_{k-1}, x_k]} f(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_k+%3D+%5Csup_%7Bx+%5Cin+%5Bx_%7Bk-1%7D%2C+x_k%5D%7D+f%28x%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle m_k = \inf_{x \in [x_{k-1}, x_k]} f(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+m_k+%3D+%5Cinf_%7Bx+%5Cin+%5Bx_%7Bk-1%7D%2C+x_k%5D%7D+f%28x%29&bg=ffffff&fg=000000&s=0&c=20201002)
We can then define the upper and lower Riemann sums of  with respect to the partition
with respect to the partition  , denoted
, denoted  and
and  , respectively, as follows.
, respectively, as follows.
![\displaystyle U(P, f) = \sum_{k=1}^n M_k [x_k - x_{k-1}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+U%28P%2C+f%29+%3D+%5Csum_%7Bk%3D1%7D%5En+M_k+%5Bx_k+-+x_%7Bk-1%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle L(P, f) = \sum_{k=1}^n m_k [x_k - x_{k-1}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+L%28P%2C+f%29+%3D+%5Csum_%7Bk%3D1%7D%5En+m_k+%5Bx_k+-+x_%7Bk-1%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Now, we can take the infimum and supremum of these over all partitions of to get the upper and lower Riemann integrals of over the interval :
![\displaystyle \overline{\int_a^b f} = \inf_{P \vdash [a, b]} U(P, f)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Coverline%7B%5Cint_a%5Eb+f%7D+%3D+%5Cinf_%7BP+%5Cvdash+%5Ba%2C+b%5D%7D+U%28P%2C+f%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \underline{\int_a^b f} = \sup_{P \vdash [a, b]} L(P, f)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cunderline%7B%5Cint_a%5Eb+f%7D+%3D+%5Csup_%7BP+%5Cvdash+%5Ba%2C+b%5D%7D+L%28P%2C+f%29&bg=ffffff&fg=000000&s=0&c=20201002)
(Where ![P \vdash [a, b]](https://s0.wp.com/latex.php?latex=P+%5Cvdash+%5Ba%2C+b%5D&bg=ffffff&fg=000000&s=0&c=20201002) means that is a partition of .)
means that is a partition of .)
In the event that  , we say that the function is Riemann integrable, and simply write
, we say that the function is Riemann integrable, and simply write 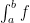 for this common value.
for this common value.
While the Riemann integral is certainly a useful tool, it has some severe restrictions. It is only defined for bounded intervals, but that is easily fixed by taking a limit as one (or both) of the endpoints goes to infinity. There are some serious problems with having a sequence of functions, as the integral of the limit may not equal the limit of the integrals. In those cases we have to either impose some pretty severe restrictions on how the sequence converges (i.e., require uniform convergence), or use more advanced tools from measure theory (namely the monotone and dominated convergence theorems with the Lebesgue integral).
Another less serious limitation is that it’s not immediately clear how to extend the Riemann integral to allow us to integrate in other spaces, namely how to integrate over  or
or  . An important, though very simple, extension of the Riemann integral that can help us rectify those problems (as well as make notation in probability theory a bit more compact) by letting us consider contour integrals is the Riemann-Stieltjes integral.
. An important, though very simple, extension of the Riemann integral that can help us rectify those problems (as well as make notation in probability theory a bit more compact) by letting us consider contour integrals is the Riemann-Stieltjes integral.
The Riemann-Stieltjes integral is defined almost exactly like the Riemann integral is above, except that instead of multiplying by the factor ![\left[x_k - x_{k-1}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5Bx_k+-+x_%7Bk-1%7D%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) in our Riemann sum, we multiply by
in our Riemann sum, we multiply by ![\left[g(x_k) - g(x_{k-1})\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5Bg%28x_k%29+-+g%28x_%7Bk-1%7D%29%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) . That is, given two functions
. That is, given two functions ![f, g : [a, b] \to \mathbb{R}](https://s0.wp.com/latex.php?latex=f%2C+g+%3A+%5Ba%2C+b%5D+%5Cto+%5Cmathbb%7BR%7D&bg=ffffff&fg=000000&s=0&c=20201002) we can define,
we can define,
![\displaystyle U(P, f, g) = \sum_{k=1}^n M_k [g(x_k) - g(x_{k-1})]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+U%28P%2C+f%2C+g%29+%3D+%5Csum_%7Bk%3D1%7D%5En+M_k+%5Bg%28x_k%29+-+g%28x_%7Bk-1%7D%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle L(P, f, g) = \sum_{k=1}^n m_k [g(x_k) - g(x_{k-1})]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+L%28P%2C+f%2C+g%29+%3D+%5Csum_%7Bk%3D1%7D%5En+m_k+%5Bg%28x_k%29+-+g%28x_%7Bk-1%7D%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
And we define the upper and lower integrals of with respect to  as
as
![\displaystyle \overline{\int_a^b f \, dg} = \inf_{P \vdash [a, b]} U(P, f, g)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Coverline%7B%5Cint_a%5Eb+f+%5C%2C+dg%7D+%3D+%5Cinf_%7BP+%5Cvdash+%5Ba%2C+b%5D%7D+U%28P%2C+f%2C+g%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \underline{\int_a^b f\, dg} = \sup_{P \vdash [a, b]} L(P, f, g)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cunderline%7B%5Cint_a%5Eb+f%5C%2C+dg%7D+%3D+%5Csup_%7BP+%5Cvdash+%5Ba%2C+b%5D%7D+L%28P%2C+f%2C+g%29&bg=ffffff&fg=000000&s=0&c=20201002)
Again, if these values coincide, we refer to this value as  . We call the integrand and the integrator.
. We call the integrand and the integrator.
Of course, now we may ask if the Riemann-Stieltjes integral has all of the properties of the traditional Riemann integral, and what new properties it may have that the Riemann integral does not. One property that’s easy to check, though, is that of linearity.
Thanks to properties of the supremum, and infimum, we know that if  is a constant and
is a constant and  is a set,
is a set,  . Carrying this into our definition of the Riemann-Stieltjes integral, we have that if is a constant, and
. Carrying this into our definition of the Riemann-Stieltjes integral, we have that if is a constant, and  are functions such that exists, then
are functions such that exists, then 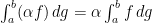 .
.
Similarly, as 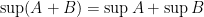 , we can show that
, we can show that 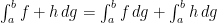 . (Of course, to use this for linearity of the integral we need to also show that
. (Of course, to use this for linearity of the integral we need to also show that 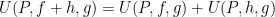 , and similarly for
, and similarly for 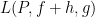 , but this follows easily by distributing the sum
, but this follows easily by distributing the sum  over the
over the  term in the Riemann sum.)
term in the Riemann sum.)

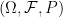
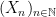



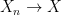





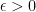

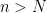



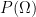
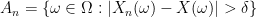
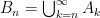
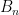
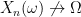

 is a random variable on the probability space
is a random variable on the probability space 
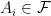 , and for the sake of simplicity that
, and for the sake of simplicity that  . The expected value of
. The expected value of ![\mathbb{E}[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D&bg=ffffff&fg=000000&s=0&c=20201002) , is
, is![\displaystyle \mathbb{E}[X] = \sum_{i=1}^n \alpha_i P(A_i)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+%5Calpha_i+P%28A_i%29&bg=ffffff&fg=000000&s=0&c=20201002) .
.![\displaystyle \mathbb{E}[X] = \sup \left\{ \mathbb{E}[Z] : 0 \leq Z \leq X \right\}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Csup+%5Cleft%5C%7B+%5Cmathbb%7BE%7D%5BZ%5D+%3A+0+%5Cleq+Z+%5Cleq+X+%5Cright%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 is a simple random variable. When
is a simple random variable. When 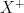 and
and  , and provided
, and provided ![\mathbb{E}[X^{+}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5E%7B%2B%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![\mathbb{E}[X^{-}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5E%7B-%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) are not both infinite, we take the expectation to be
are not both infinite, we take the expectation to be![\displaystyle \mathbb{E}[X] = \mathbb{E}[X^{+}] - \mathbb{E}[X^{-}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cmathbb%7BE%7D%5BX%5E%7B%2B%7D%5D+-+%5Cmathbb%7BE%7D%5BX%5E%7B-%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.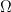 .
.![\displaystyle \mathbb{E}[X] = \int_{\Omega} X dP](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cint_%7B%5COmega%7D+X+dP&bg=ffffff&fg=000000&s=0&c=20201002)
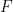 is the distribution function of
is the distribution function of ![\displaystyle \mathbb{E}[X] = \int_{\Omega} X dP = \int_{-\infty}^\infty x \, dF(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cint_%7B%5COmega%7D+X+dP+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+x+%5C%2C+dF%28x%29&bg=ffffff&fg=000000&s=0&c=20201002)
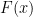 as the probability
as the probability  .
.![\displaystyle F(x) := P(X^{-1}((-\infty, x])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F%28x%29+%3A%3D+P%28X%5E%7B-1%7D%28%28-%5Cinfty%2C+x%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
 . Notice that
. Notice that  implies
implies ![(-\infty, a] \subseteq (-\infty, b]](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2C+a%5D+%5Csubseteq+%28-%5Cinfty%2C+b%5D&bg=ffffff&fg=000000&s=0&c=20201002) and so
and so![\displaystyle X^{-1}((-\infty, a]) = \{ \omega \in \Omega : X(\omega) \leq a \}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+X%5E%7B-1%7D%28%28-%5Cinfty%2C+a%5D%29+%3D+%5C%7B+%5Comega+%5Cin+%5COmega+%3A+X%28%5Comega%29+%5Cleq+a+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle \, \, = X^{-1}((-\infty, b])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%2C+%5C%2C+%3D+X%5E%7B-1%7D%28%28-%5Cinfty%2C+b%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
 ), we have that
), we have that  .
.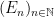 is a decreasing sequence of measurable sets (i.e.,
is a decreasing sequence of measurable sets (i.e.,  ), then
), then  , provided there exsists an
, provided there exsists an 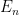 with
with  finite (in our case
finite (in our case  be a real-valued sequence that decreases to
be a real-valued sequence that decreases to ![\displaystyle \lim_{n \to \infty} F(x_n) = \lim_{n \to \infty} P(X^{-1}((-\infty, x_n]))](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+F%28x_n%29+%3D+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+P%28X%5E%7B-1%7D%28%28-%5Cinfty%2C+x_n%5D%29%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = P \left( \bigcap_{n = 1}^\infty X^{-1}((-\infty, x_n])\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+P+%5Cleft%28+%5Cbigcap_%7Bn+%3D+1%7D%5E%5Cinfty+X%5E%7B-1%7D%28%28-%5Cinfty%2C+x_n%5D%29%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = P \left( X^{-1} \left( \bigcap_{n=1}^\infty (-\infty, x_n] \right) \right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+P+%5Cleft%28+X%5E%7B-1%7D+%5Cleft%28+%5Cbigcap_%7Bn%3D1%7D%5E%5Cinfty+%28-%5Cinfty%2C+x_n%5D+%5Cright%29+%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = P(X^{-1}((-\infty, x]))](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+P%28X%5E%7B-1%7D%28%28-%5Cinfty%2C+x%5D%29%29&bg=ffffff&fg=000000&s=0&c=20201002)

 and so
and so 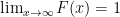 and
and  .
.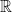 . Let
. Let 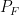 and
and  be the measure and sigma-algebra, respectively, that we get from
be the measure and sigma-algebra, respectively, that we get from 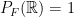 , and so
, and so  is a probability space.
is a probability space.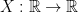 as
as  . Note that this is a random variable as
. Note that this is a random variable as![\displaystyle X^{-1}((-\infty, x]) = (-\infty, x]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+X%5E%7B-1%7D%28%28-%5Cinfty%2C+x%5D%29+%3D+%28-%5Cinfty%2C+x%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 and
and  of intervals that covers
of intervals that covers  and
and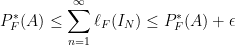
![J_n := I_n \cap (-\infty, t]](https://s0.wp.com/latex.php?latex=J_n+%3A%3D+I_n+%5Ccap+%28-%5Cinfty%2C+t%5D&bg=ffffff&fg=000000&s=0&c=20201002) and
and  ; note that
; note that  and
and 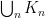 cover
cover  and
and  , respectively. Also notice that
, respectively. Also notice that  . This gives us
. This gives us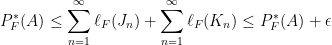
![\displaystyle \implies P_F^*(A) \leq P_F^*(A \cap (-\infty, t]) + P_F^*(A \cap (t, \infty)) \leq P_F^*(A) + \epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cimplies+P_F%5E%2A%28A%29+%5Cleq+P_F%5E%2A%28A+%5Ccap+%28-%5Cinfty%2C+t%5D%29+%2B+P_F%5E%2A%28A+%5Ccap+%28t%2C+%5Cinfty%29%29+%5Cleq+P_F%5E%2A%28A%29+%2B+%5Cepsilon&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \implies P_F^*(A) = P_F^*(A \cap (-\infty, t]) + P_F^*(A \cap (-\infty, t]^\complement)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cimplies+P_F%5E%2A%28A%29+%3D+P_F%5E%2A%28A+%5Ccap+%28-%5Cinfty%2C+t%5D%29+%2B+P_F%5E%2A%28A+%5Ccap+%28-%5Cinfty%2C+t%5D%5E%5Ccomplement%29&bg=ffffff&fg=000000&s=0&c=20201002)
 , is the distribution of some random variable.
, is the distribution of some random variable. . We can measure the length of an interval
. We can measure the length of an interval  in
in  and
and  (e.g.,
(e.g., ![{}[a, b]](https://s0.wp.com/latex.php?latex=%7B%7D%5Ba%2C+b%5D&bg=ffffff&fg=000000&s=0&c=20201002) ) as
) as .
.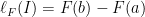 with the interval
with the interval ![(a, b]](https://s0.wp.com/latex.php?latex=%28a%2C+b%5D&bg=ffffff&fg=000000&s=0&c=20201002) , but I believe this gives the same measure in the end.)
, but I believe this gives the same measure in the end.) , as follows.
, as follows.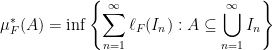
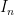 is a bounded interval. Proceeding as we would in defining the usual Lebesgue measure on
is a bounded interval. Proceeding as we would in defining the usual Lebesgue measure on  be a measure on
be a measure on  where
where

 , though with the standard Lebesgue measure we have
, though with the standard Lebesgue measure we have 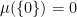 .
.
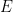 using the measure obtained from
using the measure obtained from 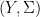 is a measurable space (i.e., a set
is a measurable space (i.e., a set  along with a sigma-algebra
along with a sigma-algebra  on
on  . That is, for each
. That is, for each  , we have
, we have  . Generally speaking, we’ll be taking
. Generally speaking, we’ll be taking 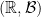 where
where  is the Borel algebra on
is the Borel algebra on  , there exists a sigma-algebra
, there exists a sigma-algebra  , called the Borel algebra on
, called the Borel algebra on  ) and is the smallest such sigma-algebra. This means that for each
) and is the smallest such sigma-algebra. This means that for each  we have
we have  and also if
and also if  . In general, given a collection
. In general, given a collection  of subsets of
of subsets of  , that is the smallest sigma-algebra on
, that is the smallest sigma-algebra on 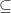 as the ordering relation) containing each
as the ordering relation) containing each  ; we say that
; we say that 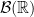 .
. . That is, if we show that
. That is, if we show that  for every
for every 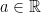 , we will have shown that
, we will have shown that 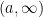 ,
,  or
or ![(-\infty, a]](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2C+a%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Using properties of sigma-algebras we can easily show that if we have all intervals of any of these forms, we have all intervals of any other form. Again, using properties of sigma-algebras it’s easy to take that and show that we have all countable unions of intervals — namely all countable unions of open intervals, i.e., all open sets.)
. Using properties of sigma-algebras we can easily show that if we have all intervals of any of these forms, we have all intervals of any other form. Again, using properties of sigma-algebras it’s easy to take that and show that we have all countable unions of intervals — namely all countable unions of open intervals, i.e., all open sets.)




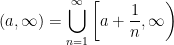
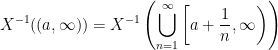

 , it’s easy to see that we also have intervals of the form
, it’s easy to see that we also have intervals of the form  . Using properties of sigma-algebras, it’s easy to show now that we have the pre-image of any open set. This tells us that if
. Using properties of sigma-algebras, it’s easy to show now that we have the pre-image of any open set. This tells us that if 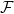 to be
to be 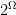 (the powerset of
(the powerset of  , and so every function on a countable sample-space is a random variable.
, and so every function on a countable sample-space is a random variable. . We can create a new measure space
. We can create a new measure space  where
where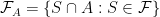

 , and any other set
, and any other set  is a subset of
is a subset of  represents the probability of
represents the probability of  to be the probability of
to be the probability of 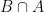 using the
using the  measure defined above. Of course, our measure and sigma-algebra are so simple that we can just write this in one line as
measure defined above. Of course, our measure and sigma-algebra are so simple that we can just write this in one line as
 given
given 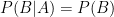 , we say that
, we say that 

 implies
implies  . Plugging into the formula for
. Plugging into the formula for 
 .
. -algebra on
-algebra on 

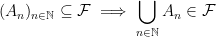
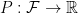 is called a measure if it satisfies the properties
is called a measure if it satisfies the properties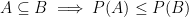

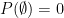
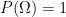 we say that our triple is in fact a probability space. This is a formalization of our intuitive ideas of what a “probability space” should be — we have a set of all things that could conceivably happen (a sample space), a family of subsets of items from that sample space (events), and a way to assign a numerical value (a probability) to each of those events. The properties of a measure, in particular, aren’t particularly surprising in this context. If we have one event contained in another event, we’d expect the probability of the larger event to be greater than the probability of the smaller event; if we have a sequence of disjoint events, the probability at least one of them occurs is the sum of their probabilities; the probability something happens is one, and the probability nothing happens is zero.
we say that our triple is in fact a probability space. This is a formalization of our intuitive ideas of what a “probability space” should be — we have a set of all things that could conceivably happen (a sample space), a family of subsets of items from that sample space (events), and a way to assign a numerical value (a probability) to each of those events. The properties of a measure, in particular, aren’t particularly surprising in this context. If we have one event contained in another event, we’d expect the probability of the larger event to be greater than the probability of the smaller event; if we have a sequence of disjoint events, the probability at least one of them occurs is the sum of their probabilities; the probability something happens is one, and the probability nothing happens is zero. and
and  . When dealing with probabilities, we’re given that
. When dealing with probabilities, we’re given that  we have
we have 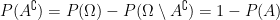 .
.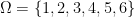 ,
,  and
and 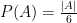 where
where 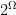 denotes the power set (the collection of all subsets) of
denotes the power set (the collection of all subsets) of 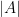 is the cardinality of
is the cardinality of 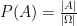 gives a measure where all events of the same size (cardinality) are equally likely.
gives a measure where all events of the same size (cardinality) are equally likely.![V_{[a, b]}(f)](https://s0.wp.com/latex.php?latex=V_%7B%5Ba%2C+b%5D%7D%28f%29&bg=ffffff&fg=000000&s=0&c=20201002) , describes how a function varies over that interval. That is, suppose
, describes how a function varies over that interval. That is, suppose  . With respect to this particular
. With respect to this particular  .
.![\left[a, b \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5Ba%2C+b+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) :
:![\displaystyle V_{[a, b]}(f) = \sup_{P \vdash [a, b]} \sum_{k=1}^n |f(x_k) - f(x_{k-1})|](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+V_%7B%5Ba%2C+b%5D%7D%28f%29+%3D+%5Csup_%7BP+%5Cvdash+%5Ba%2C+b%5D%7D+%5Csum_%7Bk%3D1%7D%5En+%7Cf%28x_k%29+-+f%28x_%7Bk-1%7D%29%7C&bg=ffffff&fg=000000&s=0&c=20201002) .
. , with
, with 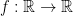 , though. For instance, consider the interval [0, 1] and the function f(x) = x. Obviously the length of the curve in
, though. For instance, consider the interval [0, 1] and the function f(x) = x. Obviously the length of the curve in  . However, if we partition the interval, the terms
. However, if we partition the interval, the terms 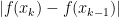 only give the vertical component of the length. Summing up all these terms, however, we will only have one, not
only give the vertical component of the length. Summing up all these terms, however, we will only have one, not  such that for any partition
such that for any partition  .
. from a metric space
from a metric space 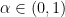 such that for every
such that for every  we have
we have 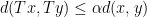 . The Banach fixed point theorem (aka the contraction theorem) says that every contraction on a non-empty complete metric space has exactly one fixed point.
. The Banach fixed point theorem (aka the contraction theorem) says that every contraction on a non-empty complete metric space has exactly one fixed point.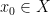 be any point. Define
be any point. Define  ,
, 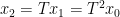 ,
, 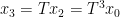 and so forth. If we write
and so forth. If we write  in terms of
in terms of  and
and , we see that
, we see that  . Now consider
. Now consider  where we assume, without loss of generality, that
where we assume, without loss of generality, that  . By the triangle inequality we have
. By the triangle inequality we have


 , so the sequence
, so the sequence  .
.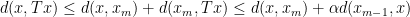
 so
so  has a fixed point. For the uniqueness of
has a fixed point. For the uniqueness of  is also a fixed point.
is also a fixed point.
 , so
, so 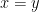 . Note that the
. Note that the 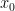 , so every sequence we construct by picking a point in
, so every sequence we construct by picking a point in 