We’ve yet to describe a way to calculate determinants in any easy way; we’ve seen some nice properties, but still have to resort to writing a non-elementary matrix as a product of elementary matrices in order to calculate its determinant. What we want to do now is describe a recursive procedure for calculating a determinant by looking at determinants of submatrices. Let’s first agree to call the submatrix of  with the
with the  -th row and
-th row and  -th column deleted the
-th column deleted the 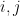 –minor of , which we’ll denote
–minor of , which we’ll denote  . So, supposing
. So, supposing
![\displaystyle A = \left[ \begin{array}{ccc} 2 & 3 & 5 \\ 7 & 9 & 11 \\ 13 & 17 & 19 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+A+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+2+%26+3+%26+5+%5C%5C+7+%26+9+%26+11+%5C%5C+13+%26+17+%26+19+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
if we delete the first row and second column we have
![\displaystyle \text{M}_{1,2}(A) = \left[ \begin{array}{cc} 7 & 11 \\ 13 & 19 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7BM%7D_%7B1%2C2%7D%28A%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+7+%26+11+%5C%5C+13+%26+19+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Let’s also note that if the first row of is all zeros except for the first entry, the determinant of is simply the determinant of 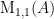 multiplied by that first entry. That is,
multiplied by that first entry. That is,
![\displaystyle \det \left[ \begin{array}{c|ccc} a_{11} & 0 & \cdots & 0 \\ \hline a_{21} & & & \\ \vdots & & \text{M}_{1,1}(A) & \\ a_{n1} & & & \end{array} \right] = a_{11} \det\left(\text{M}_{1,1}(A)\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cccc%7D+a_%7B11%7D+%26+0+%26+%5Ccdots+%26+0+%5C%5C+%5Chline+a_%7B21%7D+%26+%26+%26+%5C%5C+%5Cvdots+%26+%26+%5Ctext%7BM%7D_%7B1%2C1%7D%28A%29+%26+%5C%5C+a_%7Bn1%7D+%26+%26+%26+%5Cend%7Barray%7D+%5Cright%5D+%3D+a_%7B11%7D+%5Cdet%5Cleft%28%5Ctext%7BM%7D_%7B1%2C1%7D%28A%29%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002)
To see this, first note that we can zero out the entries in the first column below the 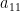 by performing a sequence of elementary row operations that don’t change the determinant. Now we clearly have
by performing a sequence of elementary row operations that don’t change the determinant. Now we clearly have
![\displaystyle \det \left[ \begin{array}{c|ccc} a_{11} & 0 & \cdots & 0 \\ \hline a_{21} & & & \\ \vdots & & \text{M}_{1,1}(A) & \\ a_{n1} & & & \end{array} \right] = a_{11} \det \left[ \begin{array}{c|ccc} 1 & 0 & \cdots & 0 \\ \hline 0 & & & \\ \vdots & & \text{M}_{1,1}(A) & \\ 0 & & & \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cccc%7D+a_%7B11%7D+%26+0+%26+%5Ccdots+%26+0+%5C%5C+%5Chline+a_%7B21%7D+%26+%26+%26+%5C%5C+%5Cvdots+%26+%26+%5Ctext%7BM%7D_%7B1%2C1%7D%28A%29+%26+%5C%5C+a_%7Bn1%7D+%26+%26+%26+%5Cend%7Barray%7D+%5Cright%5D+%3D+a_%7B11%7D+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cccc%7D+1+%26+0+%26+%5Ccdots+%26+0+%5C%5C+%5Chline+0+%26+%26+%26+%5C%5C+%5Cvdots+%26+%26+%5Ctext%7BM%7D_%7B1%2C1%7D%28A%29+%26+%5C%5C+0+%26+%26+%26+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Supposing we can write as a product of elementary matrices,  , to calculate its determinant, we can then obtain the matrix above by looking at the product
, to calculate its determinant, we can then obtain the matrix above by looking at the product
![\displaystyle \left[ \begin{array}{cc} 1 & 0 \\ 0 & E_1 \end{array} \right] \, \left[ \begin{array}{cc} 1 & 0 \\ 0 & E_2 \end{array} \right] \, \cdots \, \left[ \begin{array}{cc} 1 & 0 \\ 0 & E_m \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+E_1+%5Cend%7Barray%7D+%5Cright%5D+%5C%2C+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+E_2+%5Cend%7Barray%7D+%5Cright%5D+%5C%2C+%5Ccdots+%5C%2C+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+E_m+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Each of these is then an elementary matrix whose determinant is the same as the determinant of the associated  matrix, so we have our result.
matrix, so we have our result.
Now, applying the linearity we discussed last time,
![\displaystyle \det \left[ \begin{array}{ccc} a_{11} & \cdots & a_{1n} \\ & R_2 & \\ & \vdots & \\ & R_n & \end{array} \right] = \det \left[ \begin{array}{ccccc} a_{11} & 0 & \cdots & 0 & 0 \\ & & R_2 & & \\ & & \vdots & & \\ & & R_n & & \end{array} \right] + \det \left[ \begin{array}{ccccc} 0 & a_{12} & 0 & \cdots & 0 \\ & & R_2 & & \\ & & \vdots & & \\ & & R_n & & \end{array} \right] + ... + \det \left[ \begin{array}{ccccc} 0 & 0 & \cdots & 0 & a_{1n} \\ & & R_2 & & \\ & & \vdots & & \\ & & R_n & & \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+a_%7B11%7D+%26+%5Ccdots+%26+a_%7B1n%7D+%5C%5C+%26+R_2+%26+%5C%5C+%26+%5Cvdots+%26+%5C%5C+%26+R_n+%26+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+a_%7B11%7D+%26+0+%26+%5Ccdots+%26+0+%26+0+%5C%5C+%26+%26+R_2+%26+%26+%5C%5C+%26+%26+%5Cvdots+%26+%26+%5C%5C+%26+%26+R_n+%26+%26+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+0+%26+a_%7B12%7D+%26+0+%26+%5Ccdots+%26+0+%5C%5C+%26+%26+R_2+%26+%26+%5C%5C+%26+%26+%5Cvdots+%26+%26+%5C%5C+%26+%26+R_n+%26+%26+%5Cend%7Barray%7D+%5Cright%5D+%2B+...+%2B+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+0+%26+0+%26+%5Ccdots+%26+0+%26+a_%7B1n%7D+%5C%5C+%26+%26+R_2+%26+%26+%5C%5C+%26+%26+%5Cvdots+%26+%26+%5C%5C+%26+%26+R_n+%26+%26+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Notice that we can can zero out the elements in the first column below giving us
![\displaystyle \det \left[ \begin{array}{ccccc} a_{11} & 0 & \cdots & 0 & 0 \\ & & R_2 & & \\ & & \vdots & & \\ & & R_n & & \end{array} \right] = a_{11} \det \left( \text{M}_{11}(A) \right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+a_%7B11%7D+%26+0+%26+%5Ccdots+%26+0+%26+0+%5C%5C+%26+%26+R_2+%26+%26+%5C%5C+%26+%26+%5Cvdots+%26+%26+%5C%5C+%26+%26+R_n+%26+%26+%5Cend%7Barray%7D+%5Cright%5D+%3D+a_%7B11%7D+%5Cdet+%5Cleft%28+%5Ctext%7BM%7D_%7B11%7D%28A%29+%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002)
In general, for the -th column, we want to do a series of column swaps bringing the -th column to the front of the matrix, but keeping the other columns in order. (For this reason a single column swap won’t work, since that permutes the remaining columns.) Each time we swap columns, the determinant is multiplied by -1. If we move the -th column to the left by swapping with column 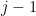 , then with column
, then with column  , and so on, we perform swaps. Thus
, and so on, we perform swaps. Thus
![\det \left[ \begin{array}{ccccc} \cdots & 0 & a_{1j} & 0 & \cdots \\ & & R_2 & & \\ & & \vdots & & \\ & & R_n & & \end{array} \right] = (-1)^{j-1} \det \left[ \begin{array}{c|ccc} a_{1j} & 0 & \cdots & 0 \\ \hline 0 & & & \\ \vdots & & \text{M}_{1,j}(A) & \\ 0 & & & \end{array} \right] = (-1)^{j-1} a_{1j} \det \left( \text{M}_{1,j}(A) \right)](https://s0.wp.com/latex.php?latex=%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+%5Ccdots+%26+0+%26+a_%7B1j%7D+%26+0+%26+%5Ccdots+%5C%5C+%26+%26+R_2+%26+%26+%5C%5C+%26+%26+%5Cvdots+%26+%26+%5C%5C+%26+%26+R_n+%26+%26+%5Cend%7Barray%7D+%5Cright%5D+%3D+%28-1%29%5E%7Bj-1%7D+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cccc%7D+a_%7B1j%7D+%26+0+%26+%5Ccdots+%26+0+%5C%5C+%5Chline+0+%26+%26+%26+%5C%5C+%5Cvdots+%26+%26+%5Ctext%7BM%7D_%7B1%2Cj%7D%28A%29+%26+%5C%5C+0+%26+%26+%26+%5Cend%7Barray%7D+%5Cright%5D+%3D+%28-1%29%5E%7Bj-1%7D+a_%7B1j%7D+%5Cdet+%5Cleft%28+%5Ctext%7BM%7D_%7B1%2Cj%7D%28A%29+%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002)
So in total we have
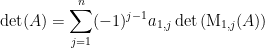
We could also perform this expansion along another row, but we’d have to perform some row swaps to move that row to the top first. Supposing we decide to expand along the -th row, we’ll perform 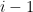 swaps, each time multiplying the determinant by -1. We’d multiply our result above, then by
swaps, each time multiplying the determinant by -1. We’d multiply our result above, then by  . Distributing that across our sum though, we note that
. Distributing that across our sum though, we note that

So, if we expand along the -th row, our formula becomes
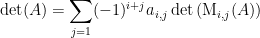
Each term of the sum with the 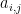 factor removed is called a cofactor; The -th cofactor, which we’ll denote
factor removed is called a cofactor; The -th cofactor, which we’ll denote  is
is

The procedure we’ve just described is known as the Laplace expansion (or cofactor expansion) for the determinant, and so now we have a more efficient way of calculating determinants. (Notice that we could expand along a column instead of a row: just repeat the above procedure on the transpose of the matrix.)




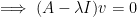



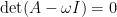

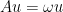


![\displaystyle A = \left[ \begin{array}{ccc} 1 & -1 & 2 \\ 2 & 2 & -3 \\ 3 & 5 & 7 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+A+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+1+%26+-1+%26+2+%5C%5C+2+%26+2+%26+-3+%5C%5C+3+%26+5+%26+7+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \text{det} \left( \left[ \begin{array}{ccc} 1 - \lambda & -1 & 2 \\ 2 & 2 - \lambda & -3 \\ 3 & 5 & 7 - \lambda \end{array} \right] \right) = -\lambda^3 + 10\lambda^2 - 34 \lambda + 60](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7Bdet%7D+%5Cleft%28+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+1+-+%5Clambda+%26+-1+%26+2+%5C%5C+2+%26+2+-+%5Clambda+%26+-3+%5C%5C+3+%26+5+%26+7+-+%5Clambda+%5Cend%7Barray%7D+%5Cright%5D+%5Cright%29+%3D+-%5Clambda%5E3+%2B+10%5Clambda%5E2+-+34+%5Clambda+%2B+60&bg=ffffff&fg=000000&s=0&c=20201002)


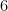





![\implies \left( \left[ \begin{array}{ccc} 1 & -1 & 2 \\ 2 & 2 & -3 \\ 3 & 5 & 7 \end{array} \right] - \left[ \begin{array}{ccc} 6 & 0 & 0 \\ 0 & 6 & 0 \\ 0 & 0 & 6 \end{array} \right] \right) \left[ \begin{array}{c} v_1 \\ v_2 \\ v_3 \end{array} \right] = 0](https://s0.wp.com/latex.php?latex=%5Cimplies+%5Cleft%28+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+1+%26+-1+%26+2+%5C%5C+2+%26+2+%26+-3+%5C%5C+3+%26+5+%26+7+%5Cend%7Barray%7D+%5Cright%5D+-+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+6+%26+0+%26+0+%5C%5C+0+%26+6+%26+0+%5C%5C+0+%26+0+%26+6+%5Cend%7Barray%7D+%5Cright%5D+%5Cright%29+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+v_1+%5C%5C+v_2+%5C%5C+v_3+%5Cend%7Barray%7D+%5Cright%5D+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002)
![\implies \left[ \begin{array}{ccc} -5 & -1 & 2 \\ 2 & -4 & -3 \\ 3 & 5 & 1 \end{array} \right] \left[ \begin{array}{c} v_1 \\ v_2 \\ v_3 \end{array} \right] = 0](https://s0.wp.com/latex.php?latex=%5Cimplies+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+-5+%26+-1+%26+2+%5C%5C+2+%26+-4+%26+-3+%5C%5C+3+%26+5+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+v_1+%5C%5C+v_2+%5C%5C+v_3+%5Cend%7Barray%7D+%5Cright%5D+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002)
![\implies \left[ \begin{array}{ccc} 1 & 0 & -\frac{1}{2} \\ 0 & 1 & \frac{1}{2} \\ 0 & 0 & 0 \end{array} \right] \left[ \begin{array}{c} v_1 \\ v_2 \\ v_3 \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cimplies+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+1+%26+0+%26+-%5Cfrac%7B1%7D%7B2%7D+%5C%5C+0+%26+1+%26+%5Cfrac%7B1%7D%7B2%7D+%5C%5C+0+%26+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+v_1+%5C%5C+v_2+%5C%5C+v_3+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\text{NS}(A - 6I) = \left\{ \left[ \begin{array}{c} \frac{1}{2} v_3 \\ -\frac{1}{2} v_3 \\ v_3 \end{array} \right] : v_3 \in \mathbb{C} \right\}](https://s0.wp.com/latex.php?latex=%5Ctext%7BNS%7D%28A+-+6I%29+%3D+%5Cleft%5C%7B+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cfrac%7B1%7D%7B2%7D+v_3+%5C%5C+-%5Cfrac%7B1%7D%7B2%7D+v_3+%5C%5C+v_3+%5Cend%7Barray%7D+%5Cright%5D+%3A+v_3+%5Cin+%5Cmathbb%7BC%7D+%5Cright%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ 0.5, \, -0.5, \, 1 \right]^T](https://s0.wp.com/latex.php?latex=%5Cleft%5B+0.5%2C+%5C%2C+-0.5%2C+%5C%2C+1+%5Cright%5D%5ET&bg=ffffff&fg=000000&s=0&c=20201002)

 . This means there is an invertible (change-of-basis) matrix
. This means there is an invertible (change-of-basis) matrix  such that
such that
 and let
and let 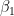 through
through 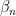 be the elements of that basis. Now, if we take the above equation and multiply by
be the elements of that basis. Now, if we take the above equation and multiply by 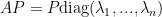

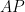 is equal to the
is equal to the  , which is just
, which is just  times the
times the 
 , we have that
, we have that .
.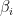 whose image under
whose image under 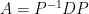 , then as we’ve just shown, the columns of
, then as we’ve just shown, the columns of 
![\displaystyle = \left[ \begin{array}{c|c|c} \beta_1 & ... & \beta_n \end{array} \right]^{-1} A \left[ \begin{array}{c|c|c} \beta_1 & ... & \beta_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cc%7Cc%7D+%5Cbeta_1+%26+...+%26+%5Cbeta_n+%5Cend%7Barray%7D+%5Cright%5D%5E%7B-1%7D+A+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cc%7Cc%7D+%5Cbeta_1+%26+...+%26+%5Cbeta_n+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = \left[ \begin{array}{c|c|c} \beta_1 & ... & \beta_n \end{array} \right]^{-1} \left[ \begin{array}{c|c|c} A \beta_1 & ... & A \beta_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cc%7Cc%7D+%5Cbeta_1+%26+...+%26+%5Cbeta_n+%5Cend%7Barray%7D+%5Cright%5D%5E%7B-1%7D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cc%7Cc%7D+A+%5Cbeta_1+%26+...+%26+A+%5Cbeta_n+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = \left[ \begin{array}{c|c|c} \beta_1 & \cdots & \beta_n \end{array} \right]^{-1} \left[ \begin{array}{c|c|c} \lambda_1 \beta_1 & \cdots & \lambda_n \beta_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cc%7Cc%7D+%5Cbeta_1+%26+%5Ccdots+%26+%5Cbeta_n+%5Cend%7Barray%7D+%5Cright%5D%5E%7B-1%7D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cc%7Cc%7D+%5Clambda_1+%5Cbeta_1+%26+%5Ccdots+%26+%5Clambda_n+%5Cbeta_n+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = \left[ \begin{array}{c|c|c} \beta_1 & \cdots & \beta_n \end{array} \right]^{-1} \left( \left[ \begin{array}{c|c|c} \beta_1 & \cdots & \beta_n \end{array} \right] \left[ \begin{array}{cccc} \lambda_1 & 0 & \cdots & 0 \\ 0 & \lambda_2 & \cdots & 0 \\ \vdots & & \ddots & \vdots \\ 0 & \cdots & 0 & \lambda_n \end{array} \right] \right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cc%7Cc%7D+%5Cbeta_1+%26+%5Ccdots+%26+%5Cbeta_n+%5Cend%7Barray%7D+%5Cright%5D%5E%7B-1%7D+%5Cleft%28+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7Cc%7Cc%7D+%5Cbeta_1+%26+%5Ccdots+%26+%5Cbeta_n+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+%5Clambda_1+%26+0+%26+%5Ccdots+%26+0+%5C%5C+0+%26+%5Clambda_2+%26+%5Ccdots+%26+0+%5C%5C+%5Cvdots+%26+%26+%5Cddots+%26+%5Cvdots+%5C%5C+0+%26+%5Ccdots+%26+0+%26+%5Clambda_n+%5Cend%7Barray%7D+%5Cright%5D+%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002)

 which performs the following:
which performs the following:![\displaystyle \left[ \begin{array}{c} 1 \\ 0 \\ 0 \end{array} \right] \mapsto \left[ \begin{array}{c} 1 \\ 2 \\ 3 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+%5Cmapsto+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+2+%5C%5C+3+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{c} 0 \\ 1 \\ 0 \end{array} \right] \mapsto \left[ \begin{array}{c} 4 \\ 5 \\ 6 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+1+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+%5Cmapsto+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+4+%5C%5C+5+%5C%5C+6+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{c} 0 \\ 0 \\ 1 \end{array} \right] \mapsto \left[ \begin{array}{c} 5 \\ 7 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D+%5Cmapsto+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+5+%5C%5C+7+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{ccc} 1 & 4 & 5 \\ 2 & 5 & 7 \\ 3 & 6 & 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+1+%26+4+%26+5+%5C%5C+2+%26+5+%26+7+%5C%5C+3+%26+6+%26+0+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 . We see that our transformation maps these basis vectors as follows:
. We see that our transformation maps these basis vectors as follows:![\displaystyle \left[ \begin{array}{c} 2 \\ 1 \\ 0 \end{array} \right] \mapsto \left[ \begin{array}{c} 6 \\ 9 \\ 12 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+2+%5C%5C+1+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+%5Cmapsto+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+6+%5C%5C+9+%5C%5C+12+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \right] \mapsto \left[ \begin{array}{c} 6 \\ 9 \\ 3 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+0+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D+%5Cmapsto+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+6+%5C%5C+9+%5C%5C+3+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{c} 3 \\ 0 \\ -1 \end{array} \right] \mapsto \left[ \begin{array}{c} -2 \\ -1 \\ 9 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+3+%5C%5C+0+%5C%5C+-1+%5Cend%7Barray%7D+%5Cright%5D+%5Cmapsto+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+-2+%5C%5C+-1+%5C%5C+9+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 basis, so let’s convert the vectors on the right to
basis, so let’s convert the vectors on the right to ![\displaystyle \left[ \begin{array}{c} 6 \\ 9 \\ 12 \end{array} \right] = \left[ \begin{array}{c} 9 \\ 6 \\ -6 \end{array} \right]_{\zeta}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+6+%5C%5C+9+%5C%5C+12+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+9+%5C%5C+6+%5C%5C+-6+%5Cend%7Barray%7D+%5Cright%5D_%7B%5Czeta%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{c} 6 \\ 9 \\ 3 \end{array} \right] = \left[ \begin{array}{c} 9 \\ -\frac{3}{4} \\ -\frac{15}{4} \end{array} \right]_{\zeta}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+6+%5C%5C+9+%5C%5C+3+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+9+%5C%5C+-%5Cfrac%7B3%7D%7B4%7D+%5C%5C+-%5Cfrac%7B15%7D%7B4%7D+%5Cend%7Barray%7D+%5Cright%5D_%7B%5Czeta%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{c} -2 \\ -1 \\ 9 \end{array} \right] = \left[ \begin{array}{c} 19 \\ \frac{7}{4} \\ - \frac{5}{2} \end{array} \right]_{\zeta}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+-2+%5C%5C+-1+%5C%5C+9+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+19+%5C%5C+%5Cfrac%7B7%7D%7B4%7D+%5C%5C+-+%5Cfrac%7B5%7D%7B2%7D+%5Cend%7Barray%7D+%5Cright%5D_%7B%5Czeta%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{ccc} 9 & 9 & 19 \\ 6 & -\frac{3}{4} & \frac{7}{4} \\ -6 & -\frac{15}{4} & -\frac{5}{2} \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+9+%26+9+%26+19+%5C%5C+6+%26+-%5Cfrac%7B3%7D%7B4%7D+%26+%5Cfrac%7B7%7D%7B4%7D+%5C%5C+-6+%26+-%5Cfrac%7B15%7D%7B4%7D+%26+-%5Cfrac%7B5%7D%7B2%7D+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![_\zeta[\tau]_\zeta](https://s0.wp.com/latex.php?latex=_%5Czeta%5B%5Ctau%5D_%5Czeta&bg=ffffff&fg=000000&s=0&c=20201002) where the right-most subscript means that inputs are in
where the right-most subscript means that inputs are in ![\displaystyle _\zeta[\tau]_\zeta = _\zeta[I]_e \, _e[\tau]_e \, _e[I]_\zeta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+_%5Czeta%5B%5Ctau%5D_%5Czeta+%3D+_%5Czeta%5BI%5D_e+%5C%2C+_e%5B%5Ctau%5D_e+%5C%2C+_e%5BI%5D_%5Czeta&bg=ffffff&fg=000000&s=0&c=20201002)
![_e[I]_\zeta](https://s0.wp.com/latex.php?latex=_e%5BI%5D_%5Czeta&bg=ffffff&fg=000000&s=0&c=20201002) refers to the
refers to the ![A := _\zeta[\tau]_\zeta](https://s0.wp.com/latex.php?latex=A+%3A%3D+_%5Czeta%5B%5Ctau%5D_%5Czeta&bg=ffffff&fg=000000&s=0&c=20201002)
![B := _e[\tau]_e](https://s0.wp.com/latex.php?latex=B+%3A%3D+_e%5B%5Ctau%5D_e&bg=ffffff&fg=000000&s=0&c=20201002)
![P := _e[I]_\zeta](https://s0.wp.com/latex.php?latex=P+%3A%3D+_e%5BI%5D_%5Czeta&bg=ffffff&fg=000000&s=0&c=20201002)
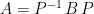
 for which there exists a
for which there exists a  and
and 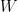 are vector spaces over the field
are vector spaces over the field 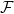 . A function
. A function  is called a linear transformation if for all scalars
is called a linear transformation if for all scalars  and for all vectors
and for all vectors  we have
we have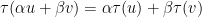
 is a basis for V. Let
is a basis for V. Let  be any vector in
be any vector in  . We then have
. We then have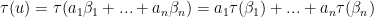 .
. , we can figure out where any other vector will be sent by
, we can figure out where any other vector will be sent by  is necessarily a basis for the range,
is necessarily a basis for the range, 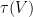 . It could be that
. It could be that 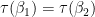 , in which case these vectors are linearly dependent and can’t both be in the basis. We do have that
, in which case these vectors are linearly dependent and can’t both be in the basis. We do have that  -dimensional with the
-dimensional with the  -dimensional with basis
-dimensional with basis  . Note that the properties of matrix multiplication tell us that any
. Note that the properties of matrix multiplication tell us that any  matrix defines a linear transformation from
matrix defines a linear transformation from 
![\displaystyle \tau(\beta_i) = \left[ \begin{array}{c} a_{1i} \\ a_{2i} \\ \vdots \\ a_{mi} \end{array} \right]_\omega](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctau%28%5Cbeta_i%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+a_%7B1i%7D+%5C%5C+a_%7B2i%7D+%5C%5C+%5Cvdots+%5C%5C+a_%7Bmi%7D+%5Cend%7Barray%7D+%5Cright%5D_%5Comega&bg=ffffff&fg=000000&s=0&c=20201002)
 . We then have
. We then have

![\displaystyle \, = b_1 \left[ \begin{array}{c} a_{11} \\ a_{21} \\ \vdots \\ a_{m1} \end{array} \right] + b_2 \left[ \begin{array}{c} a_{12} \\ a_{22} \\ \vdots \\ a_{m2} \end{array} \right] + ... + b_n \left[ \begin{array}{c} a_{1n} \\ a_{2n} \\ \vdots \\ a_{mn} \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%2C+%3D+b_1+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+a_%7B11%7D+%5C%5C+a_%7B21%7D+%5C%5C+%5Cvdots+%5C%5C+a_%7Bm1%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+b_2+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+a_%7B12%7D+%5C%5C+a_%7B22%7D+%5C%5C+%5Cvdots+%5C%5C+a_%7Bm2%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+...+%2B+b_n+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+a_%7B1n%7D+%5C%5C+a_%7B2n%7D+%5C%5C+%5Cvdots+%5C%5C+a_%7Bmn%7D+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \, = \left[ \begin{array}{cccc} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & & & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{array} \right] \left[ \begin{array}{c} b_1 \\ b_2 \\ \vdots \\ b_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%2C+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+a_%7B11%7D+%26+a_%7B12%7D+%26+%5Ccdots+%26+a_%7B1n%7D+%5C%5C+a_%7B21%7D+%26+a_%7B22%7D+%26+%5Ccdots+%26+a_%7B2n%7D+%5C%5C+%5Cvdots+%26+%26+%26+%5Cvdots+%5C%5C+a_%7Bm1%7D+%26+a_%7Bm2%7D+%26+%5Ccdots+%26+a_%7Bmn%7D+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+b_1+%5C%5C+b_2+%5C%5C+%5Cvdots+%5C%5C+b_n+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![_\omega[ \tau ]_\beta](https://s0.wp.com/latex.php?latex=_%5Comega%5B+%5Ctau+%5D_%5Cbeta&bg=ffffff&fg=000000&s=0&c=20201002)
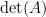



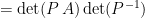
 up into a product of elementary matrices, one of which will have be of the form
up into a product of elementary matrices, one of which will have be of the form  . We know that this matrix will have determinant zero, so the product will be zero, and thus
. We know that this matrix will have determinant zero, so the product will be zero, and thus 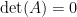 . Likewise, if
. Likewise, if  for some vectors
for some vectors  and
and ![\displaystyle \det(A) = \det \left[ \begin{array}{c} \alpha + \beta \\ R_2 \\ \vdots \\ R_n \end{array} \right] = \det \left[ \begin{array}{c} \alpha \\ R_2 \\ \vdots \\ R_n \end{array} \right] + \det \left[ \begin{array}{c} \beta \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cdet%28A%29+%3D+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Calpha+%2B+%5Cbeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Calpha+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cbeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
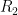 through
through 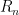 form a linearly dependent set. Then our matrix is singular so has determinant zero. The determinants on the right in the above equation are zero too, so our we have our result.
form a linearly dependent set. Then our matrix is singular so has determinant zero. The determinants on the right in the above equation are zero too, so our we have our result.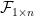 by adding a vector, call it
by adding a vector, call it  for
for  such that
such that
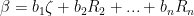
![\displaystyle \det \left[ \begin{array}{c} \alpha \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Calpha+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = \det \left[ \begin{array}{c} a_1 \zeta + a_2 R_2 + ... + a_n R_n \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+a_1+%5Czeta+%2B+a_2+R_2+%2B+...+%2B+a_n+R_n+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = \det \left[ \begin{array}{c} a_1 \zeta \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+a_1+%5Czeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = a_1 \det \left[ \begin{array}{c} \zeta \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+a_1+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Czeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \det \left[ \begin{array}{c} \beta \\ R_2 \\ \vdots \\ R_n \end{array} \right] = b_1 \det \left[ \begin{array}{c}\zeta \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cbeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+%3D+b_1+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D%5Czeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \det \left[ \begin{array}{c} \alpha + \beta \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Calpha+%2B+%5Cbeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = \det \left[ \begin{array}{c} (a_1 + b_1) \zeta + (a_2 + b_2) R_2 + ... + (a_n + b_n) R_n \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%28a_1+%2B+b_1%29+%5Czeta+%2B+%28a_2+%2B+b_2%29+R_2+%2B+...+%2B+%28a_n+%2B+b_n%29+R_n+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = (a_1 + b_1) \det \left[ \begin{array}{c} \zeta \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%28a_1+%2B+b_1%29+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Czeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = a_1 \det \left[ \begin{array}{c} \zeta \\ R_2 \\ \vdots \\ R_n \end{array} \right] + b_1 \det \left[ \begin{array}{c} \zeta \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+a_1+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Czeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+%2B+b_1+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Czeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = \det \left[ \begin{array}{c} \alpha \\ R_2 \\ \vdots \\ R_n \end{array} \right] + \det \left[ \begin{array}{c} \beta \\ R_2 \\ \vdots \\ R_n \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Calpha+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cdet+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cbeta+%5C%5C+R_2+%5C%5C+%5Cvdots+%5C%5C+R_n+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
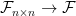 function which satisfies the following.
function which satisfies the following.
 is
is  .
.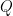 such that
such that![\displaystyle PAQ = \left[ \begin{array}{cc} I_r & 0 \\ 0 & 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+PAQ+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I_r+%26+0+%5C%5C+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
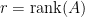 . In the above,
. In the above, ![\displaystyle A = P^{-1} \left[ \begin{array}{cc} I_r & 0 \\ 0 & 0 \end{array} \right] Q^{-1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+A+%3D+P%5E%7B-1%7D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I_r+%26+0+%5C%5C+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D+Q%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 . If we agree to also call such matrices elementary, then every square matrix is a product of elementary matrices.
. If we agree to also call such matrices elementary, then every square matrix is a product of elementary matrices. function satisfying the properties given above, we can calculate the determinant of an elementary matrix pretty easily. In the following,
function satisfying the properties given above, we can calculate the determinant of an elementary matrix pretty easily. In the following, 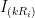 means we multiply the
means we multiply the  means we swap rows
means we swap rows  means we add
means we add 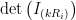

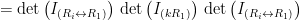
 (these are scalars in a field, so they commute)
(these are scalars in a field, so they commute)

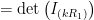

 and
and 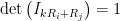 . Now we know the determinants for all elementary matrices. Since every square matrix is a product of elementary matrices, and we can split the determinant up across a product of matrices, we can even calculate the determinant of any square matrix based solely on the two properties given earlier. (Note this isn’t necessarily an efficient way to calculate the determinant, just a possible way.)
. Now we know the determinants for all elementary matrices. Since every square matrix is a product of elementary matrices, and we can split the determinant up across a product of matrices, we can even calculate the determinant of any square matrix based solely on the two properties given earlier. (Note this isn’t necessarily an efficient way to calculate the determinant, just a possible way.)![\{ [1, 0, 0]^T, [0, 1, 0]^T, [0, 0, 1]^T \}](https://s0.wp.com/latex.php?latex=%5C%7B+%5B1%2C+0%2C+0%5D%5ET%2C+%5B0%2C+1%2C+0%5D%5ET%2C+%5B0%2C+0%2C+1%5D%5ET+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) or
or ![\{ [1, 2, 0]^T, [3, 0, 1]^T, [4, 2, -1]^T \}](https://s0.wp.com/latex.php?latex=%5C%7B+%5B1%2C+2%2C+0%5D%5ET%2C+%5B3%2C+0%2C+1%5D%5ET%2C+%5B4%2C+2%2C+-1%5D%5ET+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This first basis is known as the standard basis, and in general for an
. This first basis is known as the standard basis, and in general for an ![\{ [1, 0, 0, ..., 0]^T, [0, 1, 0, ..., 0]^T, ..., [0, ..., 0, 1]^T \}](https://s0.wp.com/latex.php?latex=%5C%7B+%5B1%2C+0%2C+0%2C+...%2C+0%5D%5ET%2C+%5B0%2C+1%2C+0%2C+...%2C+0%5D%5ET%2C+...%2C+%5B0%2C+...%2C+0%2C+1%5D%5ET+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) as the standard basis, and will let
as the standard basis, and will let  denote the vector with a 1 in the
denote the vector with a 1 in the ![[1, 2, 3]^T](https://s0.wp.com/latex.php?latex=%5B1%2C+2%2C+3%5D%5ET&bg=ffffff&fg=000000&s=0&c=20201002) we implicitly mean that these are the coordinates to use with the vectors in the standard basis; these are the coefficients we multiply the
we implicitly mean that these are the coordinates to use with the vectors in the standard basis; these are the coefficients we multiply the ![\displaystyle \left[ \begin{array}{c} 1 \\ 2 \\ 3 \end{array} \right] = 1 \left[ \begin{array}{c} 1 \\ 0 \\ 0 \end{array} \right]+ 2 \left[ \begin{array}{c} 0 \\ 1 \\ 0 \end{array} \right] + 3 \left[ \begin{array}{c} 0 \\ 0 \\ 1 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+2+%5C%5C+3+%5Cend%7Barray%7D+%5Cright%5D+%3D+1+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D%2B+2+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+1+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+%2B+3+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
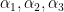 . Then what we want to do is find the values of the
. Then what we want to do is find the values of the  such that
such that![\displaystyle \alpha_1 \left[ \begin{array}{c} 1 \\ 2 \\ 0 \end{array} \right] + \alpha_2 \left[\begin{array}{c}3 \\ 0 \\ 1\end{array}\right] + \alpha_3\left[\begin{array}{c}4 \\ 2 \\ -1\end{array}\right] = \left[ \begin{array}{c} 1 \\ 2 \\ 3 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Calpha_1+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+2+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Calpha_2+%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D3+%5C%5C+0+%5C%5C+1%5Cend%7Barray%7D%5Cright%5D+%2B+%5Calpha_3%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D4+%5C%5C+2+%5C%5C+-1%5Cend%7Barray%7D%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+2+%5C%5C+3+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{ccc} 1 & 3 & 4 \\ 2 & 0 & 2 \\ 0 & 1 & -1 \end{array} \right] \left[ \begin{array}{c} \alpha_1 \\ \alpha_2 \\ \alpha_3 \end{array} \right]= \left[ \begin{array}{c} 1 \\ 2 \\ 3 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+1+%26+3+%26+4+%5C%5C+2+%26+0+%26+2+%5C%5C+0+%26+1+%26+-1+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Calpha_1+%5C%5C+%5Calpha_2+%5C%5C+%5Calpha_3+%5Cend%7Barray%7D+%5Cright%5D%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+2+%5C%5C+3+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left[ \begin{array}{c} \alpha_1 \\ \alpha_2 \\ \alpha_3 \end{array} \right] = \left[ \begin{array}{ccc} 1 & 3 & 4 \\ 2 & 0 & 2 \\ 0 & 1 & -1 \end{array} \right]^{-1} \left[ \begin{array}{c} 1 \\ 2 \\ 3 \end{array} \right] = \left[ \begin{array}{c} 5/2 \\ 3/2 \\ -3/2\end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Calpha_1+%5C%5C+%5Calpha_2+%5C%5C+%5Calpha_3+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+1+%26+3+%26+4+%5C%5C+2+%26+0+%26+2+%5C%5C+0+%26+1+%26+-1+%5Cend%7Barray%7D+%5Cright%5D%5E%7B-1%7D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+2+%5C%5C+3+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+5%2F2+%5C%5C+3%2F2+%5C%5C+-3%2F2%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 , we will write
, we will write![\displaystyle \left[ \begin{array}{c} \alpha_1 \\ \vdots \\ \alpha_n \end{array} \right]_A](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Calpha_1+%5C%5C+%5Cvdots+%5C%5C+%5Calpha_n+%5Cend%7Barray%7D+%5Cright%5D_A&bg=ffffff&fg=000000&s=0&c=20201002)
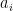 vectors in our
vectors in our 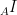 be the matrix converts the coordinates for the standard basis to coordinates in our
be the matrix converts the coordinates for the standard basis to coordinates in our 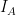 will be the matrix which converts coordinates from the
will be the matrix which converts coordinates from the ![\displaystyle I_A = \left[ \, \left. a_1 \, \right| \, \left. a_2 \, \right| \, \left. \cdots \, \right| \, a_n \, \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+I_A+%3D+%5Cleft%5B+%5C%2C+%5Cleft.+a_1+%5C%2C+%5Cright%7C+%5C%2C+%5Cleft.+a_2+%5C%2C+%5Cright%7C+%5C%2C+%5Cleft.+%5Ccdots+%5C%2C+%5Cright%7C+%5C%2C+a_n+%5C%2C+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle _AI = \left[ \, \left. a_1 \, \right| \, \left. a_2 \, \right| \, \left. \cdots \, \right| \, a_n \, \right]^{-1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+_AI+%3D+%5Cleft%5B+%5C%2C+%5Cleft.+a_1+%5C%2C+%5Cright%7C+%5C%2C+%5Cleft.+a_2+%5C%2C+%5Cright%7C+%5C%2C+%5Cleft.+%5Ccdots+%5C%2C+%5Cright%7C+%5C%2C+a_n+%5C%2C+%5Cright%5D%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 . The matrix which will take coordinates with respect to the
. The matrix which will take coordinates with respect to the 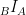 . One way to calculate
. One way to calculate 
![\displaystyle [ a_i ]_B = _BI_A [ a_i ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B+a_i+%5D_B+%3D+_BI_A+%5B+a_i+%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \, = _BI_A \left[ \begin{array}{c} 0 \\ \vdots \\ 0 \\ 1 \\ 0 \\ \vdots \\ 0 \end{array} \right]_A](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%2C+%3D+_BI_A+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+%5Cvdots+%5C%5C+0+%5C%5C+1+%5C%5C+0+%5C%5C+%5Cvdots+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D_A&bg=ffffff&fg=000000&s=0&c=20201002) (with the 1 in the
(with the 1 in the  (recall
(recall  is the notation I use for the
is the notation I use for the  )
) to
to  , then the null space of
, then the null space of  , is simply the kernel of the map.
, is simply the kernel of the map.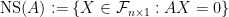
 .
. is a basis for
is a basis for  properly chosen vectors. Call these vectors
properly chosen vectors. Call these vectors  so that
so that 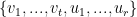 is a basis for
is a basis for  and suppose
and suppose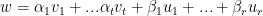
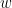 on the left by
on the left by 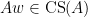 we have
we have


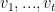 are mapped to zero by
are mapped to zero by 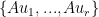 spans
spans  . If we can now show that
. If we can now show that 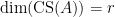 and have proven our theorem.
and have proven our theorem. such that
such that
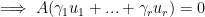
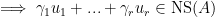


 , so
, so  . Since
. Since  , we have our result.
, we have our result. , clearly
, clearly 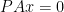 , so that
, so that  . If
. If 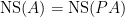 . Combining this with the above theorem we have that if
. Combining this with the above theorem we have that if 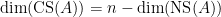
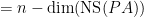
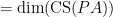
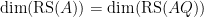 if
if  .)
.)


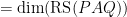
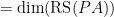

 . For this reason the theorem we proved above is known as the rank-nullity theorem.
. For this reason the theorem we proved above is known as the rank-nullity theorem.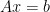 , we see that the left-hand side gives us a particular linear combination of the columns of
, we see that the left-hand side gives us a particular linear combination of the columns of ![\displaystyle x_1 \left[ \begin{array}{c} a_{11} \\ a_{21} \\ \vdots \\ a_{m1} \end{array} \right] + x_2 \left[ \begin{array}{c} a_{12} \\ a_{22} \\ \vdots \\ a_{m2} \end{array} \right] + ... + x_n \left[\begin{array}{c} a_{1n} \\ a_{2n} \\ \vdots \\ a_{mn} \end{array} \right] = \left[ \begin{array}{c} b_1 \\ b_2 \\ \vdots \\ b_m \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+x_1+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+a_%7B11%7D+%5C%5C+a_%7B21%7D+%5C%5C+%5Cvdots+%5C%5C+a_%7Bm1%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+x_2+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+a_%7B12%7D+%5C%5C+a_%7B22%7D+%5C%5C+%5Cvdots+%5C%5C+a_%7Bm2%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+...+%2B+x_n+%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+a_%7B1n%7D+%5C%5C+a_%7B2n%7D+%5C%5C+%5Cvdots+%5C%5C+a_%7Bmn%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+b_1+%5C%5C+b_2+%5C%5C+%5Cvdots+%5C%5C+b_m+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 can be expressed as a linear combination of the columns of
can be expressed as a linear combination of the columns of 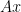 for any
for any 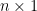 vector
vector 
 . Notice that
. Notice that  .
. differ from
differ from 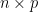 , we have that
, we have that


 . The above is telling us that linear combinations of the columns of
. The above is telling us that linear combinations of the columns of 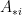 denote the
denote the ![\displaystyle AQ = \left[ \left. \sum_{i=1}^n q_{i,1} A_{*i} \, \right| \, \left. \sum_{i=1}^n q_{i,2} A_{*i} \, \right| \, ... \, \left| \, \sum_{i=1}^n q_{i,p} A_{*i} \right. \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+AQ+%3D+%5Cleft%5B+%5Cleft.+%5Csum_%7Bi%3D1%7D%5En+q_%7Bi%2C1%7D+A_%7B%2Ai%7D+%5C%2C+%5Cright%7C+%5C%2C+%5Cleft.+%5Csum_%7Bi%3D1%7D%5En+q_%7Bi%2C2%7D+A_%7B%2Ai%7D+%5C%2C+%5Cright%7C+%5C%2C+...+%5C%2C+%5Cleft%7C+%5C%2C+%5Csum_%7Bi%3D1%7D%5En+q_%7Bi%2Cp%7D+A_%7B%2Ai%7D+%5Cright.+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)




 values is arbitrary — they can be whatever we’d like them to be — but the
values is arbitrary — they can be whatever we’d like them to be — but the 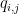 are fixed since they’re entries in
are fixed since they’re entries in  . Repeating the same argument but using rows instead of columns, or just using the above argument with
. Repeating the same argument but using rows instead of columns, or just using the above argument with  . Notice if
. Notice if  . Combined with the above we have equality when
. Combined with the above we have equality when ![PAQ = \left[ \begin{array}{cc} I_r & 0 \\ 0 & 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=PAQ+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I_r+%26+0+%5C%5C+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 is the
is the  identity matrix for some
identity matrix for some  . Since matrix multiplication is associative,
. Since matrix multiplication is associative,  . Putting the matrix into row-reduced echelon form with the
. Putting the matrix into row-reduced echelon form with the 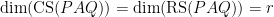 . We can show that when
. We can show that when  , using the rank-nullity theorem which we’ve yet to prove.
, using the rank-nullity theorem which we’ve yet to prove.